系数 β0 与 β1 的点估计
最小二乘估计 (least squares estimation, LSE) 是对线性回归模型 (10.1.1) 中的未知参数 β0,β1 进行点估计的经典方法. 在最小二乘估计中, 我们考虑如下最优化问题: β0,β1min 21i=1∑n(Yi−β0−β1xi)2,(10.2.1)在求解 (10.2.1) 时我们把各个 Yi 看作定值, 则求得的最优解可看作 Y1,…,Yn 的函数. 我们将 (10.2.1) 的最优解记为 β0 与 β1, 它们就是 β0 与 β1 的最小二乘点估计量. 我们先介绍如何求解最优化问题 (10.2.1), 再对 (10.2.1) 给出的点估计的合理性进行解释.
首先注意到, 最优化问题 (10.2.1) 中对 β0 与 β1 的取值未做出其它约束, 故可以考虑对目标函数S(β0,β1)=21i=1∑n(Yi−β0−β1xi)2求偏导得到驻点, 再验证驻点是否是最小值点. S(β0,β1) 的偏导数由∂β0∂S(β0,β1)=∂β1∂S(β0,β1)=−i=1∑n(Yi−β0−β1xi),−i=1∑nxi(Yi−β0−β1xi)给出, 而 S(β0,β1) 的海塞矩阵 (Hessian matrix) 则为H(β0,β1)=⎣⎡∂β02∂2S(β0,β1)∂β1∂β0∂2S(β0,β1)∂β0∂β1∂2S(β0,β1)∂β12∂2S(β0,β1)⎦⎤=[nnxnx∑i=1nxi2]而由于 x1,…,xn 不都等于同一个值, 故detH(β0,β1)=ni=1∑nxi2−n2x2=ni=1∑n(xi−x)2>0,再注意到 H(β0,β1) 的两个对角元均为正数, 可得 H(β0,β1) 为正定矩阵, 因此 S(β0,β1) 是一个强凸的可微函数, 由多元微积分知识可知, S(β0,β1) 仅存在唯一一个驻点, 且该驻点就是它的最小值点. 由此可得最优化问题 (10.2.1) 的最优解满足方程组nβ0+(i=1∑nxi)β1(i=1∑nxi)β0+(i=1∑nxi2)β1=i=1∑nYi,=i=1∑nxiYi,(10.2.2)该方程组也被称为 normal equations 1. 解 normal equations 可得β0β1=Y−β1x,=∑i=1nxi2−nx2∑i=1nxiYi−nx⋅Y=∑i=1n(xi−x)2∑i=1n(xi−x)Yi,(10.2.3)其中我们记x=n1i=1∑nxi,Y=n1i=1∑nYi.式 (10.2.3) 给出的 β0 与 β1 即为 β0 与 β1 的最小二乘估计量. 习惯上, 我们还会引入如下记号: Sxx=SxY=i=1∑n(xi−x)2,i=1∑n(xi−x)Yi=i=1∑n(xi−x)(Yi−Y),(10.2.4)则 β1 可表示为β1=SxxSxY.值得注意的是, β1 与 β0 均可看 Y1,…,Yn 的线性函数. 在得到回归系数的点估计值以后, 我们可以进一步对回归函数在任意 x 处的取值进行点估计: μ(x)=β0+β1x=Y+β1(x−x).特别地, 我们记Yi=μ(xi)=β0+β1xi,i=1,…,n.此外, 我们将ei=Yi−Yi=Yi−(β0+β1xi)称为第 i 个残差 (residual).
接下来, 我们对最小二乘估计的合理性进行解释.
最小二乘估计作为最大似然估计. 在一开始的线性回归模型 (10.1.1) 中, 我们并未指定随机误差 ε 的分布具有怎样的形式, 而只是限定其期望为 0 且方差有限. 而在许多场合下, 为了方便用概率论工具对最小二乘估计进行定量研究, 我们会进一步假定 ε 服从正态分布 N(0,σ2), 此时可以证明, 最小二乘估计 β0,β1 也是 β0,β1 的最大似然估计: 注意到 ε∼N(0,σ2) 时, 有 Yi∼N(β0+β1xi,σ2), 故 (Y1,…,Yn) 的联合概率密度函数为f(y;β0,β1,σ2,x)=i=1∏n2πσ1exp(−2σ2(yi−β0−β1xi)2),其中记 x=(x1,…,xn), y=(y1,…,yn). 而将 f(y;β0,β1,σ2,x) 当中的 x 与 y 固定, 并把未知参数 β0,β1,σ2 作为自变量, 即可得到似然函数 L(β0,β1,σ2;x,y). 相应的对数似然函数为lnL(β0,β1,σ2;x,y)=−2σ21i=1∑n(yi−β0−β1xi)2−2nln(2πσ2),(10.2.5)而关于 β0 与 β1 的对数似然方程则为00=∂β0∂lnL(β0,β1,σ2;x,y)=σ21i=1∑n(yi−β0−β1xi),=∂β1∂lnL(β0,β1,σ2;x,y)=σ21i=1∑nxi(yi−β0−β1xi).立刻可看出上述方程组与 normal equations (10.2.2) 具有相同的形式. 由此可得如下结论: 当随机误差 ε 服从正态分布 N(0,σ2) 时, β0 与 β1 的最大似然估计量就是最小二乘估计量.
(⋆) 最小二乘估计作为最佳无偏线性估计. 我们还可以从最佳无偏线性估计的角度解释最小二乘估计的合理性. 设 (x1,Y1),…,(xn,Yn) 为一组样本, 考虑 β0 与 β1 的关于 Y1,…,Yn 具有线性形式的点估计量: β^1=i=1∑naiYi,β^0=i=1∑nbiYi,其中 a1,…,an 与 b1,…,bn 为待定系数, 且要求它们具有无偏性. 我们希望在线性与无偏性的约束下, 找到使得均方误差MSEβ1(β^1)=E[(β^1−β1)2] 与 MSEβ0(β^0)=E[(β^0−β0)2]对任意的 β0,β1 与 σ2>0 均能取到最小值的系数 a1,…,an 与 b1,…,bn. 为了后面推导的方便, 我们罗列如下事实:
1. | Y1,…,Yn 相互独立. |
2. | E[Yi]=β0+β1xi, Var(Yi)=σ2. |
首先考虑 β1 的最佳无偏线性估计. β1=∑i=1naiYi 的无偏性要求β1=E[i=1∑naiYi]=β0⋅i=1∑nai+β1⋅i=1∑naixi,∀β0,β1由 β0 与 β1 的任意性, 可得到i=1∑nai=0,i=1∑naixi=1.接下来我们将均方误差 MSEβ1(β^1) 进行展开, 并注意到 β^1 的无偏性, 可得MSEβ1(β^1)==Var(β1)=Var(i=1∑naiYi)i=1∑nai2Var(Yi)=σ2i=1∑nai2.因此 β1 的最佳线性无偏估计的系数 a1,…,an 为如下带约束最优化问题的解: a1,…,anmin 21i=1∑nai2s.t. i=1∑nai=0, i=1∑naixi=1.上述问题是一个典型的凸优化问题, 可以用拉格朗日乘子法求出最优解: 该问题的拉格朗日函数为L(a1,…,an,μ,λ)=21i=1∑nai2+μi=1∑nai+λ(i=1∑naixi−1).故最优性条件为0=0=∂ai∂L(a1,…,an,μ,λ)=ai+μ+λxi,i=1∑nai,0=i=1∑naixi−1.上述方程组的解为ai=∑jxj2−nx2xi−x,μ=∑jxj2−nx2x,λ=−∑jxj2−nx21.不难发现由上述系数 a1,…,an 给出的线性估计量就是 β1 的最小二乘估计量. 同理可证明 β0 的最佳线性估计量就是最小二乘估计量, 相关的计算与验证过程交给读者完成.
(⋆) Normal equations (10.2.2) 有非常直观的几何解释. 设 (x1,Y1),…,(xn,Yn) 为一组样本, 仍将 Y1,…,Yn 看作是定值, 则 Y=(Y1,…,Yn) 可看作 Rn 当中的一个点或一个向量. 记 x=(x1,…,xn), 并用 1 表示分量均为 1 的 n 维向量. 令V={β01+β1x∣β0,β1∈R},则当 x 的元素不全相等时, V 构成了 Rn 的一个二维子空间, 而最优化问题 (10.2.1) 则可以等价表示为z∈Vmin 21∥Y−z∥2,其中 ∥⋅∥ 表示欧氏空间 Rn 当中的标准 ℓ2 范数. 换句话说, 求解 β0 与 β1 的最小二乘估计量, 等价于在子空间 V 中找到一个点 (我们将其记为 Y) 使得它与 Y 的距离最小. 由欧氏空间的几何关系, 不难理解这个与 Y 的距离最小的点 Y 应当使得 Y−Y 与二维子空间 V 正交 (见图 1). 由于 {1,x} 是子空间 V 的一组基, 可知 Y−Y 与 V 正交当且仅当 Y−Y 与 1 和 x 均正交, 即0=0=1T(Y−Y),xT(Y−Y).将 Y=β01+β1x 代入并进行化简, 可得0=0=i=1∑n(Yi−β0−β1xi),i=1∑nxi(Yi−β0−β1xi),上述方程组正是 normal equations.
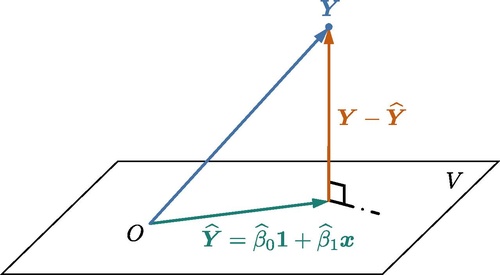 图 1. Normal equations 几何直观示意图.
图 1. Normal equations 几何直观示意图. 最小二乘估计的偏差与均方误差
本小节中, 我们对 β0 与 β1 的最小二乘估计的偏差与均方误差进行分析. 设自变量 x 与因变量 Y 之间的确服从 (10.1.1) 给出的线性回归模型. 注意到 E[Yi]=β0+β1xi, 可得E[β1]====E[i=1∑nSxxxi−xYi]i=1∑nSxxxi−x(β0+β1xi)Sxxβ0i=1∑nSxxxi−x+Sxxβ1i=1∑n(xi2−xix)Sxxβ1(i=1∑nxi2−nx2)=β1,其中利用了 ∑i=1n(xi−x)=0, 故 β1 是 β1 的一个无偏估计量. β1 的均方误差也就等于其方差, 为Var(β1)===Var(i=1∑nSxx(xi−x)Yi)i=1∑nSxx2(xi−x)2Var(Yi)Sxx2∑i=1n(xi−x)2⋅σ2=Sxxσ2.
对于 β0 则有E[β0]=E[Y−β1x]=(β0+β1x)−β1x=β0,其中利用了 E[Y]=β0+β1x 以及 β1 的无偏性, 故可得 β0 是无偏的. 而 β0 的均方误差也就等于其方差, 为Var(β0)====Var(Y−β1x)Var(i=1∑n(n1−Sxxxi−xx)Yi)i=1∑n(n1−Sxxxi−xx)2Var(Yi)σ2i=1∑n(n1−Sxxxi−xx)2,而i=1∑n(n1−Sxxxi−xx)2===i=1∑n(n21+Sxx2x2(xi−x)2−n2x(xi−x))n1+Sxxx2i=1∑n(xi−x)2−n2xi=1∑n(xi−x)n1+Sxxx2,故Var(β0)=σ2(n1+Sxxx2).
最后, 我们对 β0 与 β1 的协方差进行计算: Cov(β0,β1)=====Cov(Y−β1x,β1)Cov(n1i=1∑nYi,Sxx1j=1∑n(xj−x)Yj)−Var(β1)⋅xnSxx1i,j=1∑n(xj−x)Cov(Yi,Yj)−Sxxσ2xnSxx1i=1∑n(xi−x)σ2−Sxxσ2x−Sxxσ2x,其中倒数第二步是由于 Y1,…,Yn 相互独立且 Var(Yi)=σ2.
需要指出, 上述推导均不需要假定 ε1,…,εn 服从正态分布.
方差 σ2 的点估计
为了对线性回归模型 (10.1.1) 中随机误差 ε 的方差 σ2 进行估计, 我们注意到, 若估计量 β0,β1 的值与 β0,β1 的真值非常接近, 则直观上可以认为εi=≈Yi−β0−β1xiYi−β0−β1xi=ei.注意到随机误差 εi 不可观测但 ei 是一个可观测的统计量, 这提示着我们残差 ei 在对 σ2 的估计中将起到关键作用. 不难看出 ei 的期望为 0, 而为了计算 ei 的方差, 我们注意到ei===Yi−(Y−β1x)−β1xi=Yi−Y−β1(xi−x)Yi−n1j=1∑nYj−Sxxxi−xj=1∑n(xj−x)Yj(1−n1−Sxx(xi−x)2)Yi−j=i∑(n1+Sxx(xi−x)(xj−x))Yj,而由于 Y1,…,Yn 之间相互独立, 故Var(ei)======(1−n1−Sxx(xi−x)2)2Var(Yi)+j=i∑(n1+Sxx(xi−x)(xj−x))2Var(Yj)[1+(n1+Sxx(xi−x)2)2−2(n1+Sxx(xi−x)2)]σ2+j=i∑(n1+Sxx(xi−x)(xj−x))2σ2σ2[1−2(n1+Sxx(xi−x)2)+j=1∑n(n1+Sxx(xi−x)(xj−x))2]σ2[1−n2−Sxx2(xi−x)2+j=1∑n(n21+Sxx2(xi−x)2(xj−x)2+nSxx2(xi−x)(xj−x))]σ2[1−n2−Sxx2(xi−x)2+n1+Sxx2(xi−x)2j=1∑n(xj−x)2+nSxx2(xi−x)j=1∑n(xj−x)]σ2(1−n1−Sxx(xi−x)2),其中最后一步利用了 ∑j=1n(xj−x)2=Sxx 以及 ∑j=1n(xj−x)=0. 接下来, 我们令SSRes=i=1∑n(Yi−Yi)2=i=1∑nei2,(10.2.6)并将其称为残差平方和 (residual sum of squares), 则有E[SSRes]=i=1∑nσ2(1−n1−Sxx(xi−x)2)=(n−2)σ2.由此可得 σ2 的一个无偏估计量为σ2=n−21SSRes=n−21i=1∑n(Yi−β0−β1xi)2.(10.2.7)
残差平方和 SSRes 的一个更加便于计算的表达式为SSRes=SST−β1SxY,其中 SST=i=1∑n(Yi−Y)2,(10.2.8)SST 被称为校正平方和 (corrected sum of squares). 我们将上式的证明留作习题.
需要说明的是, σ2 的无偏性并不需要假定 ε 服从正态分布.
脚注