8.1. 区间估计与置信区间
设总体的分布函数为 , 其中未知参数 的所有可能取值构成集合 , 且为简单起见, 设 是 上的一个区间. 在点估计问题中, 我们通过构造合适的统计量 , 基于获得的样本值来给出未知参数 的单个估计值. 然而, 在某些实际问题中, 我们可能不仅需要进行点估计, 还希望基于样本对这个点估计的精度进行某种推断. 例如, 我们可能希望找到一个阈值, 使得点估计值与真实值的距离能够以大概率小于等于该阈值, 那么我们就可以用这个阈值来代表估计的精度. 由于真实的总体未知, 我们也只能基于样本值来给出这个阈值, 故这个阈值也对应于一个统计量. 将以上想法进行整理后, 我们就得到了如下问题: 应当如何构造点估计量 以及一个阈值统计量 , 使得不等式对任意 成立, 其中 是一个事先定好的足够小的实数. 不难看出上述问题也等价于如何构造统计量 与 , 使得(8.1.1)其中 是一个事先定好的足够小的实数. 换句话说, 我们希望找到一个依赖于样本的区间 , 使得无论总体的真实参数 是什么, 这个区间能够覆盖住真实参数 的概率至少为 . 我们把这一类问题称为区间估计 (interval estimation) 问题, 而将满足条件 (8.1.1) 的端点为统计量的区间 称为 的置信区间 (confidence interval), 并把 叫作该置信区间的置信水平 (confidence level) 1. 我们还经常将 与 分别称为置信下限与置信上限 (lower/upper confidence limit).
对于置信水平为 的置信区间 , 我们可以认为 衡量了区间估计的可靠性, 而 则衡量了区间估计的精度. 不难理解可靠性与精度之间是存在一定矛盾的, 一般来说, 在样本容量 受限的情形下, 我们不可能把区间估计的可靠性与精度都同时提升到一个很高的水平. 在经典的频率学派区间估计理论中, 我们采取的方案是先给定可靠性的一个下限 (也即确定置信水平), 在保证这个下限的前提下尽量提升区间估计的精度 2. 换句话说, 在针对给定的 求解置信区间 时, 我们会在保证其置信水平至少为 的前提下, 尽量让该区间的宽度 取得越小越好. 通常, 这将迫使我们让 的概率尽可能地下探到 (但不得低于 ); 特别是, 当总体 是连续型随机变量时, 我们通常就按要求来求置信区间.
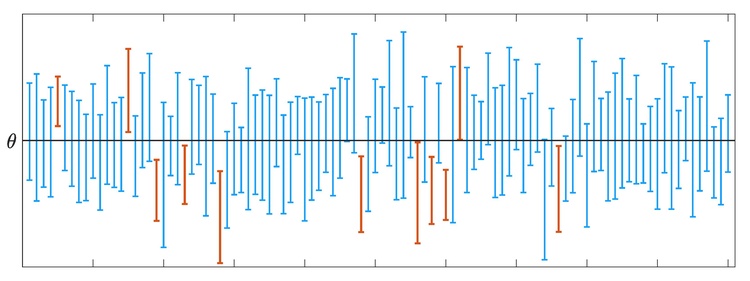
需要注意的是, 式 (8.1.1) 当中出现的参数 是被作为一个确定性的量处理的, 也就是说, 我们目前是以频率学派的视角来对待区间估计问题的, 而这也要求我们在理解 (8.1.1) 的含义时需要格外小心. 特别是, 我们不能认为式 (8.1.1) 体现了未知参数 的统计规律 (因为 是一个确定性的量). 一种解释 (8.1.1) 含义的方式如下: 设总体的参数为某个确定性的 , 而我们通过从这个总体中反复地抽样, 按照统计量 与 来大量重复上述置信区间的构造流程 (比方说重复 次), 从而获得 个置信区间的结果. 由于每次抽样获得的样本值是不同的, 这 个区间也互不相同. 则平均而言, 在这大量的区间估计给出的结果中, 把参数真值 覆盖住的区间所占的比例将至少为 ; 可参考图 1 给出的图示.
例 8.1.1 (方差已知时正态总体期望的区间估计). 设总体 服从正态分布 , 其中方差 已知而期望 未知, 为总体 的一组样本, 我们希望对期望 进行区间估计, 找出其置信水平为 的一个置信区间.

注 8.1.2. 例 8.1.1 考虑的是总体服从正态分布的情形. 而若总体不服从正态分布但其方差 已知, 且样本容量 足够大, 则由中心极限定理可得 近似服从标准正态分布, 此时我们可以依照例 8.1.1 的步骤对期望 的置信区间进行近似求解, 并最终得到其置信水平为 的置信区间可以近似由式 (8.1.2) 给出.
注 8.1.3. 对于某些场合, 我们可能只是想估计出未知参数 的一个上界, 并在保证一定可靠性的前提下让这个上界尽可能接近参数的真值. 换句话说, 给定 , 我们只需找到一个尽量小的统计量 使得(8.1.3)即可. 我们将满足 (8.1.3) 的统计量 称作置信水平为 的单侧置信上界 (one-sided upper confidence bound). 对于单侧置信上界, 其估计精度可以直接由它的大小来衡量, 即单侧置信上界越小则估计精度越高. 同理也可定义单侧置信下界 (one-sided lower confidence bound) 的概念. 此外, 我们也将形如的置信区间称作单侧置信区间 (one-sided confidence interval).
以例 8.1.1 考虑的情形为例, 给定置信水平 , 则未知参数 的两个单侧置信区间可以分别取为(注意上式中用到的上分位数为 而非 ).
我们可以将例 8.1.1 的区间估计步骤进行推广, 得到求解置信区间的一个较为一般的方法:
1. | 构造一个依赖于样本 与参数值 的随机变量 , 使得 的分布不再与未知参数有关 (换句话说, 在取不同的 时所服从的分布都是相同的). 我们将该随机变量 称作一个枢轴量 (pivotal quantity). 在例 8.1.1 当中, 枢轴量即为 . |
2. | 找出两个合适的常数 与 , 使得特别是, 若 为连续型随机变量, 则找出满足的常数 . 在例 8.1.1 当中, 由于枢轴量服从标准正态分布, 故可以取 . 而取 可以使得最终构造出来的置信区间宽度最小. |
3. | 尝试将不等式 等价地变形为如下形式: 若这样的等价变形可行, 则可知 的一个置信水平为 的置信区间为 |
我们将上述求解置信区间的方法称作枢轴量法. 需要注意的是, 枢轴量法并非万能, 其中枢轴量的构造对于总体分布的形式较为复杂的情形往往是比较困难的.
注 8.1.4. 若总体的未知参数为 (它可以是标量也可以是多维向量), 而我们想对 进行区间估计, 其中 为一个实值函数, 则此时 的置信水平为 的置信区间 需满足如下条件: 其中区间端点 仍要求为统计量. 此时依然可以考虑用枢轴量法构造置信区间, 不过我们会要求枢轴量的形式为 , 也就是说它只和 与 有关; 另一方面, 我们仍然要求 的分布与 无关. 此时通过即可构造 的置信区间.
上述情形的一个特例是总体存在多个未知标量参数 , 而我们想对其中一个未知标量参数 进行区间估计. 此时其余的参数 被称为多余参数 (nuisance parameter, 其它中文称谓还包括冗余参数、讨厌参数、干扰参数等). 存在多余参数 时, 的置信水平为 的置信区间 则需满足如下条件: 其中 为 的取值范围, 为多余参数 的取值范围. 对于存在多余参数的情形, 若要用枢轴量法求 的置信区间, 则要求枢轴量 只和 与 有关而与 无关, 但同时要求 的分布与 和 均无关. 此时由构造的 的置信区间则可用于多余参数 未知的情形.
在接下来的几节中, 我们将针对几类常见的区间估计问题, 介绍其置信区间的求解流程. 我们只给出 (双侧) 置信区间的构造流程, 但读者可自行推导相应的单侧置信上界与单侧置信下界.
脚注
1. | ^ 注意到若 是 的置信水平, 那么任何小于等于 的正实数也都是 的置信水平. 有些场合为了表意上的确切, 当给定置信区间而谈论其置信水平时, 我们是指满足 (8.1.1) 的 当中最大的那个值. |
2. | ^ 这套区间估计的范式是由统计学家 Jerzy Neyman 首先建立的. |